
The Cognitive Debt of Digging Through Preprints
Your Brain on MIT Media Lab
1. One Media Lab preprint is worth a thousand think-pieces
Before I start slandering another arxiv preprint, I want to be clear that I really do appreciate the effort, skill, and craft that went into this particular piece of research. It’s not easy to write 200 pages and 100 figures worth of novel content, and my critique is mainly of how this research will be framed and interpreted by the media. Additionally, like much out of MIT Media Lab, the creativity of this work is its strongest attribute and deserves praise.
However, this manuscript — Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task — is already being interpreted in an apocalyptic manner. This Twitter thread, for example, has about 17 million impressions over the last 24 hours, making it probably the most influential interpretation of this research:


Is ChatGPT making us cognitively bankrupt? Is it resulting in a 47% reduction in our brain connectivity? And does this “first brain scan study" out of MIT even conclude that? No. Of course not.
TIME Magazine uses slightly less strong language, but seems to directionally agree, unfortunately:

Adoption of AI technology is well on its way to becoming the ur-topic in culture, science, and dining room table discussion. ChatGPT currently has about 5% odds of being selected as the TIME Person of the Year, with the general concept of “AI” coming in at ~20% and Pope Leo XIV at ~30% (who chose his name primarily to signal his views that AI will profoundly shift society). As such, the research around AI will only become more and more fraught. When a scientific paper is expected to stake out a moral claim and be pigeonholed into an ideological framework, it doesn’t bode well for the field. And when you add onto this a stratum of political beliefs and in-group signaling…

…then it becomes challenging for the public to fairly evaluate a work in this field:
2. The field of “Is AI bad for your mind?”

This study subjected 54 Boston-area university-affiliated subjects (ranging from undergraduates to post-docs) to the following experiment:
They were divided into three groups (n=18): “brain-only”, “search engine”, and “LLM”.
Each would come to three sessions where they would write an essay in response to an SAT-style prompt, as well as a fourth optional session. In the first three, they would use either their brain, their brain + search engine, or their brain + LLM to write the essay. In the fourth optional session, the brain-only people used an LLM and the other sections had no assistance. Only about half the participants returned for the fourth session (n=9)!
Before beginning the essay, they answered a questionnaire and were hooked up to a 32-electrode EEG headset, which would monitor their brain activity during the task. They also answered a survey after each session.
Great, simple enough, right? Place yourself into the shoes of the testing subject here. You are paid $100 to come three times, answer some questions, and have an MIT researcher monitor your brain activity with EEG while you write a short essay. And for a third of you, they’re telling you to use an LLM to write the essay! So, you’ll probably prompt the LLM, iterate a bit, copy-paste some text, and lightly edit it to suit your fancy.
Very intuitively this will have two effects, both of which the researchers found.
First, since you didn’t directly write most of the words in your essay, you should have more trouble directly quoting it than someone who typed the essay from scratch.

Ignoring the erroneous y-axis label and figure caption (both of which should read “# of participants in each group who provided a correct quote”), this hypothesis was supported by the experiment. Basically none of the subjects in the LLM group could quote an entire sentence from their essay, which indicates to me that they were primarily viewing the task as “use this LLM to generate an essay”. This is a very different task than “write an essay,” and the people in the other two groups could mostly quote their essay directly. As you might expect, the subjects who had access to a search engine were actually better at quoting their essays, which makes sense because they probably included famous quotes in their essays, that could be easily recalled verbatim.
The second effect that should have been obvious is that your neural activity when you interact with an LLM and generate an essay will probably be different than someone writing an essay. I mean, at the very least, they involve different activities. Someone writing the essay will be doing a lot more typing, whereas someone generating an essay with an LLM will probably be mousing more, reading more text, and spending more time editing vs writing directly. So it stands to reason that if you monitor their neural activity with an EEG, you’ll see some difference. And the researchers did see this:
“In conclusion, the directed connectivity analysis reveals a clear pattern: writing without assistance increased brain network interactions across multiple frequency bands, engaging higher cognitive load, stronger executive control, and deeper creative processing. Writing with AI assistance, in contrast, reduces overall neural connectivity, and shifts the dynamics of information flow. In practical terms, a LLM might free up mental resources and make the task feel easier, yet the brain of the user of the LLM might not go as deeply into the rich associative processes that unassisted creative writing entails.”
But all this is localized to their performance during the task. Can we conclude anything about how LLMs affect learning long-term, or whether some sort of “cognitive debt” will build up if we become dependent on LLMs?
No, we cannot. At least, not from the experiments shown in this manuscript.
3. Stop generalizing
Not only are the participants in this paper extremely WEIRD, but they’re all from top Boston-area universities and they’re all having fun writing an essay while hooked up to EEG. I’ve participated in a couple of academic studies of this nature. In one, I was enclosed in a zip-up sauna chamber enclosing all of my body but my head and forced to sweat profusely for about an hour. Sweating intensely for an hour is uncomfortable to most people, but I was having a great time because it was a unique experience and I was surrounded by prodding scientists taking my measurements. Similarly, this research cannot and should not generalize to how normal/most/any people learn during a class assignment. Notice that nearly everyone is having a good time and is fully satisfied with their essay they wrote for $33 and for the benefit of science:
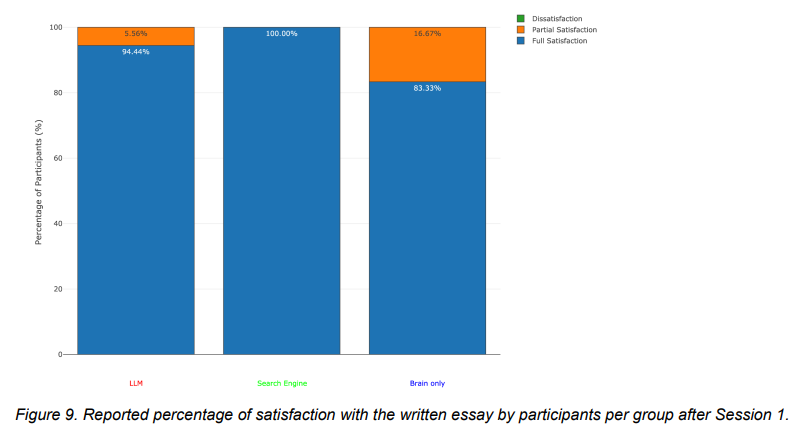
Is it likely that anyone in this study is “learning” here? Everyone in this study already did exceptionally on their SAT test because they’re currently enrolled at MIT or Harvard or Wellesley
4. Testing for everything is cool, but then you’re also kind of testing nothing
The biggest reason for cautious skepticism, in my estimation, is that this study tested virtually every possible qualitative and quantitative measure in order to determine statistical significance and evaluate interesting-looking findings. It’s not clear that any of these were pre-registered suitably, and though they did use False Discovery Rate (FDR) correction for certain tests, they didn’t provide details on this methodology, and this is notably a much less-strict way of avoiding false positives than, say, FWER. It also basically guarantees that in spite of adjusting your p-values, you’re still bound to get tons of false positives.
“For all the sessions we calculated dDTF for all pairs of electrodes 32 × 32 = 1024 and ran repeated measures analysis of variance (rmANOVA) within the participant and between the participants within the groups. Due to complexity of the data and volume of the collected data we ran rmANOVA ≤ 1000 times each. To denote different levels of significance in figures and results, we adopted the following convention:
p < 0.05 was considered statistically significant and is marked with a single asterisk (*)
p < 0.01 with a double asterisk (**)
p < 0.001 with a triple asterisk (***)”
That’s just the EEG results! It provides perhaps tens of thousands of possible correlations to test for. Hundreds of these will meet their criteria for statistical significance by chance, probably even with FDR implemented.
I asked my neuroscientist girlfriend about the EEG results. It took some coaxing because, unlike me, she is admirably hesitant to opine on things outside her narrow domain of expertise. But she eventually paraphrased this quote from Tim Urban (this article was from 2017, wow she has a good memory)!
“Imagine that the brain is a baseball stadium, its neurons are the members of the crowd, and the information we want is, instead of electrical activity, vocal cord activity. In that case, EEG would be like a group of microphones placed outside the stadium, against the stadium’s outer walls. You’d be able to hear when the crowd was cheering and maybe predict the type of thing they were cheering about. You’d be able to hear telltale signs that it was between innings and maybe whether or not it was a close game. You could probably detect when something abnormal happened. But that’s about it.”
I think EEG may have gotten a little more developed as a tool in the last decade (partly due to the valiant efforts of this paper’s lead author) but ultimately it triggers an involuntary but severe reaction of skepticism, especially when I see these sorts of conclusions:
The critical connection from left parietal (P7) to right temporal (T8) regions demonstrated highly significant group differences (p=0.0002, dDTF: Brain-only group=0.053, LLM group=0.009). This P7→T8 pathway was complemented by enhanced connectivity from parieto-occipital regions to anterior frontal areas (PO4→AF3: p=0.0025, Brain-only group=0.024, LLM group=0.009)
Someone who knows more about EEG than I do should comment what they think of this kind of analysis. But my main worry is that it could be very hard to disentangle actual effects with an impact on human learning with AI tools from trivial artifacts having to do with whether the subjects were typing more or reading and editing more, for example.
In addition, they also did a bajillion other tests, presumably some of which could have been omitted or not explored further if they didn’t show interesting findings. Most were included anyway (hats off to the researchers for this transparency, I really do appreciate it)!
Nearly a dozen survey questions, each of which could be compared for any of the four sessions, as well as combinations thereof.
The results of the calibration tests for the EEG experiments (mental math and memory tests). [These weren’t included as far as I can tell]
Extensive natural language processing (much done by other AI models) which examines latent space embedding clusters.
The length of the essays as well as the in-group variability in that length.

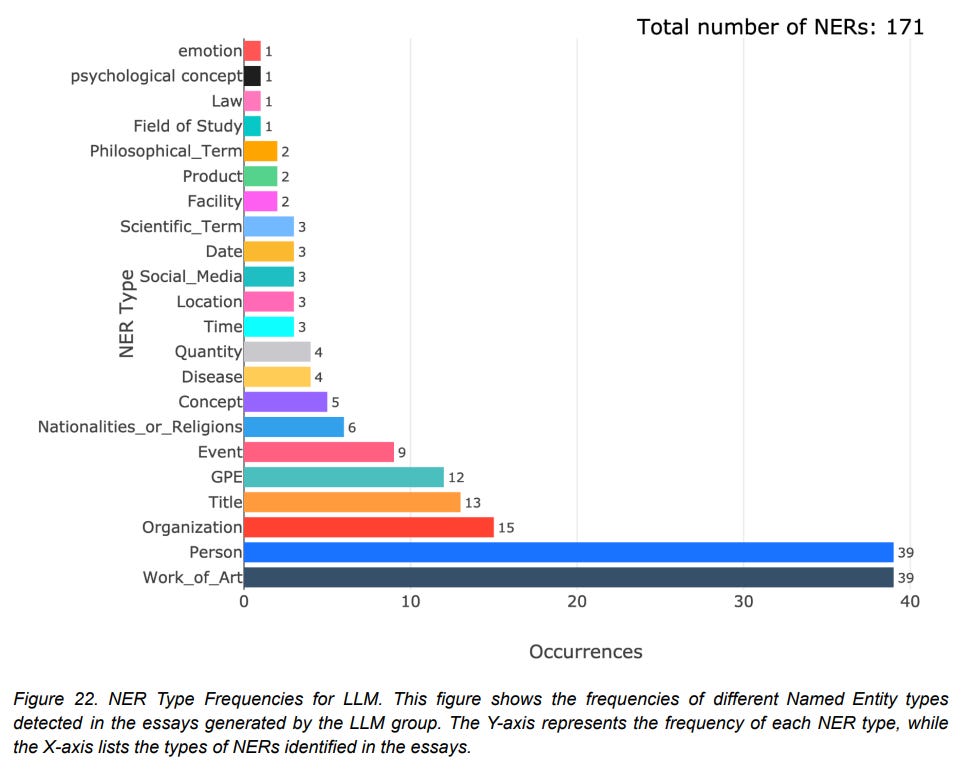
Figure 22 from: Kosmyna, Nataliya, et al. 2025. Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task. arXiv:2506.08872. Licensed under CC BY-NC-SA 4.0. “Named entities” recognition with a ton of categories.

Figure 26 from: Kosmyna, Nataliya, et al. 2025. Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task. arXiv:2506.08872. Licensed under CC BY-NC-SA 4.0. N-gram analysis. This data mostly looks like noise to me.

Figure 35 from: Kosmyna, Nataliya, et al. 2025. Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task. arXiv:2506.08872. Licensed under CC BY-NC-SA 4.0. They had an AI analyze the subjects’ interactions with the LLM and classify these interactions, doing tons of manipulations to this data and even creating “ontology graphs” for each of the essay subjects.
They had AI judges (with an agentic pipeline) and human judges evaluate each of the essays and score them across a number of parameters.
They performed cluster analyses on the post-essay interviews as well!


Smartly, the researchers for the most part tried to avoid drawing firm conclusions from any of these techniques, but that is not going to stop others from doing so!
5. Motivated reasoning is a powerful drug
I worry that the research on the effects of artificial intelligence on humans is going to quickly silo itself into subfields of “How AI is evil and destroying the world,” and “How AI will immanentize the eschaton.”
With this manuscript, you can see some telltale signs of the former.
The researchers included a prompt-injection attack to prevent others from using AI tools to help summarize or understand their work:

Additionally, in the lead author’s interview with TIME, she notes:
“She also found that LLMs hallucinated a key detail: Nowhere in her paper did she specify the version of ChatGPT she used, but AI summaries declared that the paper was trained on GPT-4o. “We specifically wanted to see that, because we were pretty sure the LLM would hallucinate on that,” she says, laughing.”
This would be a weird gotcha to begin with, except that the LLMs were in fact correct! The preprint does at one point mention that 4o was used (perhaps this was unintentionally included):

Additionally, at the end of the paper, this bizarre acknowledgement of the energy cost was included:
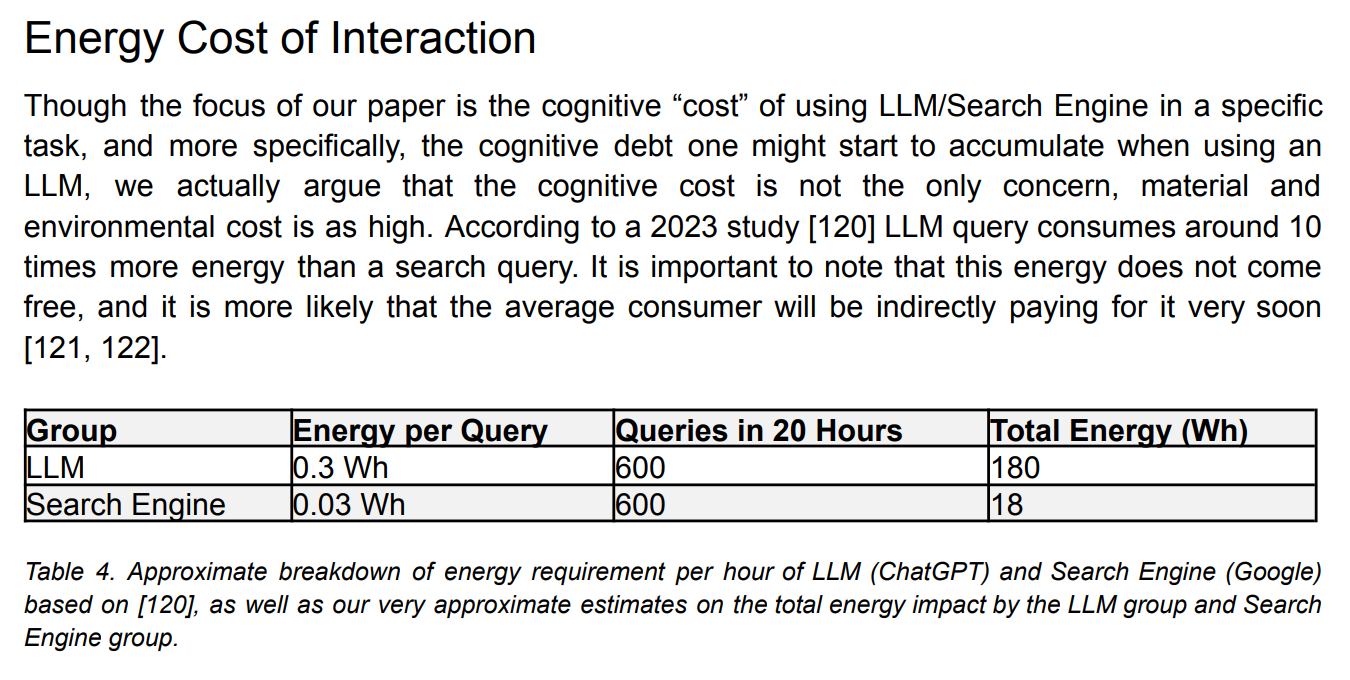
180 Wh of energy use is extremely little, especially given that this represents querying an AI every 2 minutes for 20 hours straight. Andy Masley has a great explainer on why the energy use from LLMs is actually minuscule and not worth spending your energy (no pun intended) getting worked up about.
For reference, that this is about the energy consumed in a single use of your coffee maker, according to Andy on Twitter.
Unlike my last blog post on an MIT preprint, this preprint is very much not fraudulent. It’s probably playing a little loose with frequentist statistics, has too small of a sample size for the neural monitoring it’s trying to do, and tries to generalize its findings broader than is warranted, but with that being said it’s actually a very impressive work that is fairly creative in how it uses a wide range of tools. And it’s just a preprint, and will likely get tightened up and improved significantly before it gets published.
The authors of this article, especially Kosmyna, the lead author who did the lion’s share of what looks to have been extremely laborious experimental design and implementation, deserve praise! They put out a thought-provoking paper into the public domain, inviting public criticism, feedback, and open peer review, a call with which I am happy to comply. It’s not their fault that the majority of the internet commentariat will use their research to make broad claims about AI poisoning the minds of the youth or pointing out flaws in their methodology to undermine the whole field of research.
Ultimately, I think it will be a massive scientific challenge to properly understand the effects of LLM use on learning. Intuitively, it’s likely terrible for students’ learning to copy/paste text from LLMs to submit their assignments. However, it’s potentially a near-miraculous technology for students who want to learn but don’t have access to high quality schools or personalized instruction. Personally, I feel that my own AI use has dramatically augmented my learning, but I might feel differently if I was still in an era of my life where I had to choose whether to cheat on my homework assignments with an LLM. I can say that I wrote this entire blog post manually (don’t ask me to quote sentences perfectly from it though). I did make use of Gemini 2.5 Pro to ask it questions about EEG and statistics, which I interpreted skeptically, as I interpret anything I read online.
I also had Gemini make me a picture of a cat wearing an EEG headset, for the social media preview image. Enjoy:

AI is best when used as a tool to help you think, instead of doing the thinking for you. I only started using AI in March, and it has helped me organize and work through my ideas immensely. I think best through conversation. People get bored, or aren’t in the right head space to listen to me go on and on about something I want to work out. AI “converses” with me until I’m the one getting tired. That is the value of this tool for me. I think some are just framing the technology incorrectly.
You're being quite generous! Sounds like this paper is heavily p-hacked, has all the usual flaws of pop psychology, cannot prove anything interesting by design and is written by people with a clear agenda. Just another day in academia!